

Haotian|Web3DA
Haotian|Web3DA
用戶暫無簡介
- 讚賞
- 點讚
- 留言
- 轉發
- 分享
以太坊10周年,什麼天才少年 @VitalikButerin 打造Crypto宇宙帝國等歌功頌德的話就不說了,就談幾點期許吧:
1)以太坊最大的敵人不是外部競爭對手的高TPS,恰恰是自己制造“技術內卷陷阱”。各種堆疊且復雜但實用性不及預期的技術敘事,正在消耗以太坊的戰略重心。當務之急應調整layer2諸侯割據的分散局面,回歸統一且高效的layer1高性能大戰略。
2)UltraSound Money的“大通縮”願景終會到來。EIP-1559的燃燒通縮機制和POS質押收益的通脹經濟模型稱得上精妙。燃燒機制+POS質押收益+Layer2 Fee 反哺,這套組合拳一旦有效運轉,以太坊勢必會走向“大通縮時代”,相比比特幣有限的價值捕獲能力,以太坊多層收益模型疊加的“長期預期”會有壓倒性優勢;
3)以太坊版本微策略絕對是一次史詩級的大利好,用好這個由華爾街驅動的正向飛輪,比其他“共享安全”之類的技術敘事包裝有效多了。因此以太坊需要一個像 @saylor 那樣的“布道者”,根本無需太多概念技術化的華麗包裝,僅“全球可編程數字資產結算層”一個定位,就足夠華爾街消化並炒作很多年;
4)AI大戰略會是以太坊的“救贖”機會。讓智能合約原生調用AI能力,讓AI Agent應用在以太坊上實現再復興,讓去中心化共識成爲AI+Crypto的基礎設施,唯有“AI大戰略”能夠把以太坊從單純DeFi套娃的金融困境中
查看原文1)以太坊最大的敵人不是外部競爭對手的高TPS,恰恰是自己制造“技術內卷陷阱”。各種堆疊且復雜但實用性不及預期的技術敘事,正在消耗以太坊的戰略重心。當務之急應調整layer2諸侯割據的分散局面,回歸統一且高效的layer1高性能大戰略。
2)UltraSound Money的“大通縮”願景終會到來。EIP-1559的燃燒通縮機制和POS質押收益的通脹經濟模型稱得上精妙。燃燒機制+POS質押收益+Layer2 Fee 反哺,這套組合拳一旦有效運轉,以太坊勢必會走向“大通縮時代”,相比比特幣有限的價值捕獲能力,以太坊多層收益模型疊加的“長期預期”會有壓倒性優勢;
3)以太坊版本微策略絕對是一次史詩級的大利好,用好這個由華爾街驅動的正向飛輪,比其他“共享安全”之類的技術敘事包裝有效多了。因此以太坊需要一個像 @saylor 那樣的“布道者”,根本無需太多概念技術化的華麗包裝,僅“全球可編程數字資產結算層”一個定位,就足夠華爾街消化並炒作很多年;
4)AI大戰略會是以太坊的“救贖”機會。讓智能合約原生調用AI能力,讓AI Agent應用在以太坊上實現再復興,讓去中心化共識成爲AI+Crypto的基礎設施,唯有“AI大戰略”能夠把以太坊從單純DeFi套娃的金融困境中

- 讚賞
- 點讚
- 留言
- 轉發
- 分享
看到 @plumenetwork 分享了一組RWA賽道的數據,7月份一個月,Plume鏈上RWA持有者數量暴增55%,突破16萬大關,與此同時TVL也突破了3.2億美元。此外, $PLUME 還實現了Pre-IPO的股權代幣化等等。問題來了,這波數據增長的背後意味着什麼?
答案其實很簡單,說明RWA賽道已經從“概念驗證期”邁入“商業化落地”超級週期?
1)16萬RWA持有者意味着,RWA資產不再是少數機構玩家的專屬遊戲,而是真正觸達了普通用戶的剛需。Pre-IPO股權代幣化就是最好的例證——原本只有PE、VC等機構才能參與的“上市前股權投資”,現在普通散戶也能通過代幣化方式低門檻參與,直接打破了傳統金融的準入壁壘。
2)55%的月增長則說明,RWA賽道正在從“萌芽期”進入“爆發期”,當傳統金融資產能夠像加密資產一樣絲滑交易時,這個市場的真正想象空間才會被打開。Plume作爲RWAFi的倡導者,就不止喫先發紅利那麼簡單了,享有的會是整個賽道爆發的結構性機會;
3)3.2億美元的TVL其實算市場真金白銀投出來的信任票。當TVL逐日增長,就說明RWA不再是很邊緣的小衆賽道,而是具備了和主流DeFi叫板的規模效應。而事實上,也只有當傳統資產大規模“上鏈”逐漸有了規模效應,Plume提前卡位的戰略價值才會凸顯;
具體數據Dashboard如下:
查看原文答案其實很簡單,說明RWA賽道已經從“概念驗證期”邁入“商業化落地”超級週期?
1)16萬RWA持有者意味着,RWA資產不再是少數機構玩家的專屬遊戲,而是真正觸達了普通用戶的剛需。Pre-IPO股權代幣化就是最好的例證——原本只有PE、VC等機構才能參與的“上市前股權投資”,現在普通散戶也能通過代幣化方式低門檻參與,直接打破了傳統金融的準入壁壘。
2)55%的月增長則說明,RWA賽道正在從“萌芽期”進入“爆發期”,當傳統金融資產能夠像加密資產一樣絲滑交易時,這個市場的真正想象空間才會被打開。Plume作爲RWAFi的倡導者,就不止喫先發紅利那麼簡單了,享有的會是整個賽道爆發的結構性機會;
3)3.2億美元的TVL其實算市場真金白銀投出來的信任票。當TVL逐日增長,就說明RWA不再是很邊緣的小衆賽道,而是具備了和主流DeFi叫板的規模效應。而事實上,也只有當傳統資產大規模“上鏈”逐漸有了規模效應,Plume提前卡位的戰略價值才會凸顯;
具體數據Dashboard如下:
- 讚賞
- 點讚
- 1
- 轉發
- 分享
IiDc Icion :
:
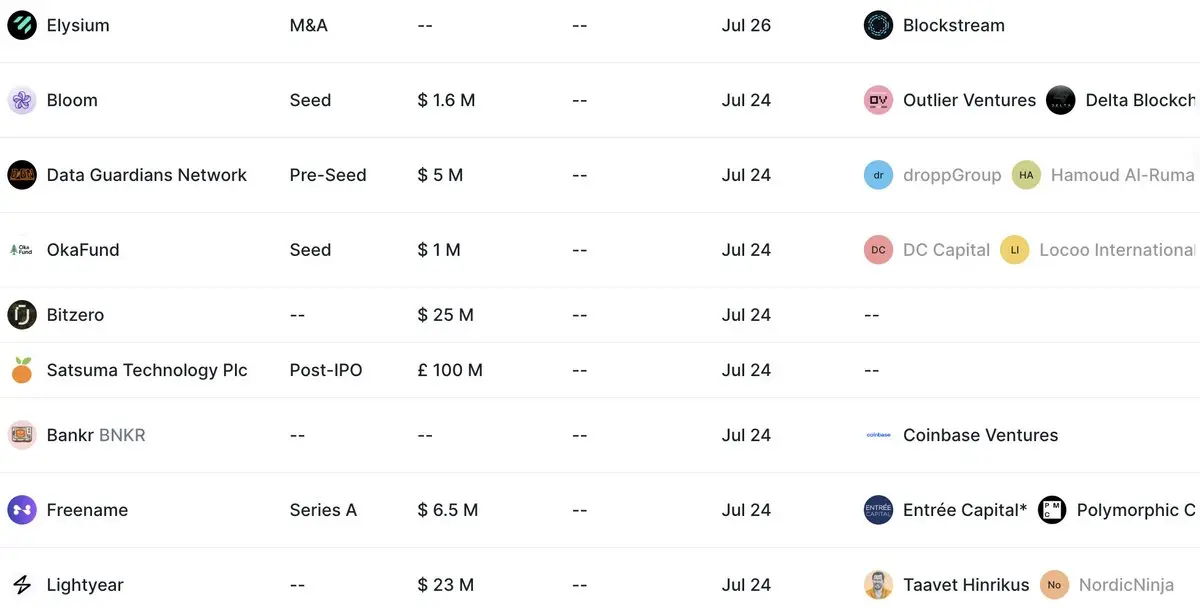
好吧,還是沒有漲。團隊太專業了。網絡釣魚觀察了一下最近在一級投資市場受青睞的項目,發現一個共性:都傾向於“混合創新”,用web3的技術infra來承載web2商業模式經過驗證的成熟商業邏輯。
比如, @go_lightyear 把傳統股票ETF投資邏輯搬到Web3、 @HilbertCapital 專攻數字資產量化策略、 @bitcoin2100m 做加密資產專業配置、@ElysiumLab_io 打造比特幣日常支付錢包等等。
這些項目,大多屬於融合創新的範疇,本質上和一些web3項目“借殼上市”以及一些美股儲備加密資產涉足Crypto背後的運作邏輯一致。
爲什麼會出現這種趨勢? 說實在的,背後有三個核心原因:
1)純原生鏈上創新項目遭遇天花板。不僅用戶規模難以突破圈層,商業模式也高度依賴Tokenomics激勵,關鍵是敘事和業務設計也陷入了“自嗨”困境,這在流動性相對匱乏的低迷市場,顯然會非常被動;
2)監管環境的“加密友好”特性顯現。BTC、ETH的ETF現貨,GENIUS、CLARITY法案的確立,華爾街金融機構的FOMO入場等等,都讓加密資產從原本的小衆投機標的變成了更主流化的金融衍生品。毋庸置疑,這種情況下,主動擁抱傳統金融成熟的商業模式或主動尋找web3有可用性的技術infra等混合創新方向都會是“香餑餑”;
3)用戶的投資需求也趨於成熟化。原本加密用戶往往在意產品或協議是不是去中心化,並按共識強度給項目
查看原文比如, @go_lightyear 把傳統股票ETF投資邏輯搬到Web3、 @HilbertCapital 專攻數字資產量化策略、 @bitcoin2100m 做加密資產專業配置、@ElysiumLab_io 打造比特幣日常支付錢包等等。
這些項目,大多屬於融合創新的範疇,本質上和一些web3項目“借殼上市”以及一些美股儲備加密資產涉足Crypto背後的運作邏輯一致。
爲什麼會出現這種趨勢? 說實在的,背後有三個核心原因:
1)純原生鏈上創新項目遭遇天花板。不僅用戶規模難以突破圈層,商業模式也高度依賴Tokenomics激勵,關鍵是敘事和業務設計也陷入了“自嗨”困境,這在流動性相對匱乏的低迷市場,顯然會非常被動;
2)監管環境的“加密友好”特性顯現。BTC、ETH的ETF現貨,GENIUS、CLARITY法案的確立,華爾街金融機構的FOMO入場等等,都讓加密資產從原本的小衆投機標的變成了更主流化的金融衍生品。毋庸置疑,這種情況下,主動擁抱傳統金融成熟的商業模式或主動尋找web3有可用性的技術infra等混合創新方向都會是“香餑餑”;
3)用戶的投資需求也趨於成熟化。原本加密用戶往往在意產品或協議是不是去中心化,並按共識強度給項目
- 讚賞
- 點讚
- 留言
- 轉發
- 分享
圍繞這次以太坊版“微策略Summer”熱潮, $ETH 真的能復制BTC微策略的“正向飛輪”嗎?談若幹個人觀點:
1)ETH微策略確實是效仿BTC微策略的成功範本,短期會有很多美股公司嘗試Fomo,並形成一波正向飛輪。暫且不管美股的操盤主體如何,真金白銀的傳統機構資金和股民買盤力量,拿 $ETH 作爲儲備資產這事實打實把以太坊帶出了長期疲軟狀態。
換句話說,Fomo帶動漲這是幣圈牛市不變的鐵律,只不過這次Fomo的主體不再是幣圈純散戶了,而是華爾街的真金白銀,至少驗證了ETH終於擺脫了純依賴幣圈堆疊敘事的困局,開始吸引圈外增量資金;
2)BTC更接近“數字黃金”的儲備資產定位,價值相對穩定且預期明確,而ETH本質上是一個“生產性資產”,其價值與以太坊網路的使用率、Gas費收入、生態發展等多重因素綁定。這意味着,ETH作爲儲備資產的波動性和不確定性更大。
一旦以太坊生態遇到較大的技術安全問題,或者監管層對DeFi、Staking等功能施壓,ETH做儲備資產面臨的風險和波動變量可比BTC大多了。所以BTC版微策略的敘事邏輯可以借鑑,但不代表市場定價估值邏輯也可以保持一致;
3)以太坊生態相比BTC有更成熟的DeFi infra積累和更豐富的敘事延展性。通過質押(staking)機制,ETH可以產生約3-4%的原生收益率,這使其相當於加密世界的“鏈上生息國債”。
機構Buy in這套故事
查看原文1)ETH微策略確實是效仿BTC微策略的成功範本,短期會有很多美股公司嘗試Fomo,並形成一波正向飛輪。暫且不管美股的操盤主體如何,真金白銀的傳統機構資金和股民買盤力量,拿 $ETH 作爲儲備資產這事實打實把以太坊帶出了長期疲軟狀態。
換句話說,Fomo帶動漲這是幣圈牛市不變的鐵律,只不過這次Fomo的主體不再是幣圈純散戶了,而是華爾街的真金白銀,至少驗證了ETH終於擺脫了純依賴幣圈堆疊敘事的困局,開始吸引圈外增量資金;
2)BTC更接近“數字黃金”的儲備資產定位,價值相對穩定且預期明確,而ETH本質上是一個“生產性資產”,其價值與以太坊網路的使用率、Gas費收入、生態發展等多重因素綁定。這意味着,ETH作爲儲備資產的波動性和不確定性更大。
一旦以太坊生態遇到較大的技術安全問題,或者監管層對DeFi、Staking等功能施壓,ETH做儲備資產面臨的風險和波動變量可比BTC大多了。所以BTC版微策略的敘事邏輯可以借鑑,但不代表市場定價估值邏輯也可以保持一致;
3)以太坊生態相比BTC有更成熟的DeFi infra積累和更豐富的敘事延展性。通過質押(staking)機制,ETH可以產生約3-4%的原生收益率,這使其相當於加密世界的“鏈上生息國債”。
機構Buy in這套故事

- 讚賞
- 點讚
- 留言
- 轉發
- 分享
爲什麼 $ETH 的新高對山寨幣市場非常重要?
1)作爲技術敘事的龍頭項目,山寨幣市場技術敘事的市場信心回歸要建立在市場對ETH的技術路線圖、產品協議應用落地願景的再信任基礎上,而長期飽受價格低迷影響的以太坊唯有新高情緒能再度點燃其技術敘事領導力信心;
2)ETH生產的不止是單一技術敘事項目,其大生態項目之間的技術邏輯關聯、TVL流動性可組合性、互相定價和評估體系等都由以太坊的市場基本面決定並直接影響帶動,ETH雄起具有牽一發而動全身之效;
3)ETH大生態沉澱了太多預期不達的老敘事,DeFi能否二次復興,NFT能否再掀文藝浪潮,layer2是否真有Mass Adoption價值,RWA新敘事能否牽引主升浪等等。在市場低迷期這些被情緒過度打壓的敘事,一旦ETH破新高估值邏輯被修復,則可能啓動一輪摧枯拉朽般的輪動行情;
查看原文1)作爲技術敘事的龍頭項目,山寨幣市場技術敘事的市場信心回歸要建立在市場對ETH的技術路線圖、產品協議應用落地願景的再信任基礎上,而長期飽受價格低迷影響的以太坊唯有新高情緒能再度點燃其技術敘事領導力信心;
2)ETH生產的不止是單一技術敘事項目,其大生態項目之間的技術邏輯關聯、TVL流動性可組合性、互相定價和評估體系等都由以太坊的市場基本面決定並直接影響帶動,ETH雄起具有牽一發而動全身之效;
3)ETH大生態沉澱了太多預期不達的老敘事,DeFi能否二次復興,NFT能否再掀文藝浪潮,layer2是否真有Mass Adoption價值,RWA新敘事能否牽引主升浪等等。在市場低迷期這些被情緒過度打壓的敘事,一旦ETH破新高估值邏輯被修復,則可能啓動一輪摧枯拉朽般的輪動行情;
- 讚賞
- 點讚
- 留言
- 轉發
- 分享
肉眼可見要TGE的項目越來越多了,但山寨幣市場的基本盤似乎並沒有太大改善:
1)以太坊還盤在低位尚未能有效開啓一輪新的山寨季行情,漲多少才行不好說,但情緒必須到位,至少要等大乙太主導的技術敘事信仰歸位;
2)現在頂着流動性枯竭、技術敘事荒、無空投口碑效應的各種負面Buff來啓動TGE,雖說是項目方無奈之舉,但換個角度看,目前有勇氣市場低谷期發幣然後再後續運維做大的項目,比那些依然等待流動性充沛時發幣的項目要靠譜很多吧;
3)比特幣的獨舞和山寨幣的落寞對比早已經極化,但不能指望純靠比特幣的溢出效應來拯救山寨幣市場,山寨幣需從敘事大於天的虛無中完成內生價值自證,並從過去無交付、無PMF的純炒作模式中脫困才行。
查看原文1)以太坊還盤在低位尚未能有效開啓一輪新的山寨季行情,漲多少才行不好說,但情緒必須到位,至少要等大乙太主導的技術敘事信仰歸位;
2)現在頂着流動性枯竭、技術敘事荒、無空投口碑效應的各種負面Buff來啓動TGE,雖說是項目方無奈之舉,但換個角度看,目前有勇氣市場低谷期發幣然後再後續運維做大的項目,比那些依然等待流動性充沛時發幣的項目要靠譜很多吧;
3)比特幣的獨舞和山寨幣的落寞對比早已經極化,但不能指望純靠比特幣的溢出效應來拯救山寨幣市場,山寨幣需從敘事大於天的虛無中完成內生價值自證,並從過去無交付、無PMF的純炒作模式中脫困才行。
- 讚賞
- 點讚
- 留言
- 轉發
- 分享
基于以太坊未来两年的技术路线图,分享若干“技术突破”可能....为价格带来支撑的方向(E卫兵特供):
1)zkEVM layer1集成
实施时间线:2025年Q4-2026年Q2完成主网部署;
技术目标:
-99%区块在10秒内完成验证;
-零知识证明验证成本降低80%;
实现意义:
-USDC、USDT等稳定币在以太坊主链上的市场占有率会进一步扩大,每日Gas消耗量相应提升,直接推动ETH通缩;
-zkEVM零知识证明技术为传统金融机构提供合规隐私保障,机构大规模DeFi应用场景有望被激活;
2)RISC-V执行新架构
实施时间线:2025年下半年开始研发,2026-2030年分阶段缓慢推进;
技术目标:
- 智能合约执行效率提升3-5倍;
- Gas成本降低50-70%;
- 开源指令集架构替代当前EVM,与现代硬件加速技术更好兼容;
实现意义:
- 执行性能的量级提升将催生全新的应用场景,比如:高频交易、实时游戏、AI推理、小额支付、微交易等;
- 更低的Gas成本将重新激活小额交易场景,显著扩大用户基础和使用频次,形成ETH需求的正向循环;
3)Layer1-Layer2生态协同
实施时间线:2025年Q4开始,2026-2027年持续优化;
技术目标:
- 实现L1与主要L2(Arbitrum、Optimism、Base等)无缝互操作;
- 现在分散流动性约为1200
1)zkEVM layer1集成
实施时间线:2025年Q4-2026年Q2完成主网部署;
技术目标:
-99%区块在10秒内完成验证;
-零知识证明验证成本降低80%;
实现意义:
-USDC、USDT等稳定币在以太坊主链上的市场占有率会进一步扩大,每日Gas消耗量相应提升,直接推动ETH通缩;
-zkEVM零知识证明技术为传统金融机构提供合规隐私保障,机构大规模DeFi应用场景有望被激活;
2)RISC-V执行新架构
实施时间线:2025年下半年开始研发,2026-2030年分阶段缓慢推进;
技术目标:
- 智能合约执行效率提升3-5倍;
- Gas成本降低50-70%;
- 开源指令集架构替代当前EVM,与现代硬件加速技术更好兼容;
实现意义:
- 执行性能的量级提升将催生全新的应用场景,比如:高频交易、实时游戏、AI推理、小额支付、微交易等;
- 更低的Gas成本将重新激活小额交易场景,显著扩大用户基础和使用频次,形成ETH需求的正向循环;
3)Layer1-Layer2生态协同
实施时间线:2025年Q4开始,2026-2027年持续优化;
技术目标:
- 实现L1与主要L2(Arbitrum、Optimism、Base等)无缝互操作;
- 现在分散流动性约为1200
- 讚賞
- 點讚
- 留言
- 轉發
- 分享
最近觀察AI行業,發現個越來越“下沉”的變化:從原先拼算力集中和“大”模型的主流共識中,演變出了一條偏向本地小模型和邊緣計算的分支。
這一點,從Apple Intelligence覆蓋5億設備,到微軟推出Windows 11專用3.3億參數小模型Mu,再到谷歌DeepMind的機器人“脫網”操作等等都能看出來。
會有啥不同呢?雲端AI拼的是參數規模和訓練數據,燒錢能力是核心競爭力;本地AI拼的是工程優化和場景適配,在保護隱私、可靠性和實用性上會更進一步。(主要通用模型的幻覺問題會嚴重影響垂類場景滲透)
這其實對web3 AI會有更大的機會,原來大家拼“通用化”(計算、數據、算法)能力時自然被傳統Giant大廠壟斷,套上去中心化的概念就想和谷歌、AWS、OpenAI等競爭簡直癡人說夢,畢竟沒有資源優勢、技術優勢,也更沒有用戶基礎。
但到了本地化模型+邊緣計算的世界,區塊鏈技術服務面臨的形勢可就大爲不同了。
當AI模型運行在用戶設備上時,如何證明輸出結果沒有被篡改?如何在保護隱私的前提下實現模型協作?這些問題恰恰是區塊鏈技術的強項...
一句話:只有當AI真正“下沉”到每個設備時,去中心化協作才會從概念變成剛需?
#Web3AI 項目與其繼續在通用化賽道裏內卷,不如認真思考怎麼爲本地化AI浪潮提供基礎設施支持?
這一點,從Apple Intelligence覆蓋5億設備,到微軟推出Windows 11專用3.3億參數小模型Mu,再到谷歌DeepMind的機器人“脫網”操作等等都能看出來。
會有啥不同呢?雲端AI拼的是參數規模和訓練數據,燒錢能力是核心競爭力;本地AI拼的是工程優化和場景適配,在保護隱私、可靠性和實用性上會更進一步。(主要通用模型的幻覺問題會嚴重影響垂類場景滲透)
這其實對web3 AI會有更大的機會,原來大家拼“通用化”(計算、數據、算法)能力時自然被傳統Giant大廠壟斷,套上去中心化的概念就想和谷歌、AWS、OpenAI等競爭簡直癡人說夢,畢竟沒有資源優勢、技術優勢,也更沒有用戶基礎。
但到了本地化模型+邊緣計算的世界,區塊鏈技術服務面臨的形勢可就大爲不同了。
當AI模型運行在用戶設備上時,如何證明輸出結果沒有被篡改?如何在保護隱私的前提下實現模型協作?這些問題恰恰是區塊鏈技術的強項...
一句話:只有當AI真正“下沉”到每個設備時,去中心化協作才會從概念變成剛需?
#Web3AI 項目與其繼續在通用化賽道裏內卷,不如認真思考怎麼爲本地化AI浪潮提供基礎設施支持?
AWS-1.33%
- 讚賞
- 點讚
- 留言
- 轉發
- 分享
1)技術視角看,Robinhood選擇站隊Arbitrum的Nitro和當初Coinbase站隊Optimism的OP Stack技術棧並沒有啥兩樣。但Base的表現已經證明了一個規律:技術棧的成功不等於母鏈的成功。
Base的崛起更多是Coinbase的品牌效應+合規資源+用戶導流的結果,某種程度上也給Robinhood棲身於Arbitrum一定指導意義。
這意味着,短期看並不能證明 $ARB 的幣價被低估(對比看 $OP 的表現),但長期看,一旦Robinhood這次瞄準的“美股上鏈”場景跑通,可能會改變原本layer2作爲以太坊layer1擴展方案“有技術無落地”的尷尬局面,會給以太坊生態L1+L2都開拓出一條前所未有的Mass Adoption宏大路徑。
2)Coinbase做layer2更多還是通用layer2的解決方案,主要沿用了過往DeFi、GameFi、MEME等交易導向的場景,而Robinhood這次可能會不太一樣,會走專業化layer2的方向,專門爲傳統金融上鏈定制一套契合的鏈上基礎設施?
盡管OP-Rollup的交易確認時間也能做到亞秒級,但這類交易安全性本身都還在7天欺詐驗證的樂觀Rollup範疇內,而Robinhood的新layer2要處理股票T+0結算、實時風控、合規要求等特性,可能需要在layer2的虛擬機層面、共識機制、數據結構上做深度定制,把Lay
查看原文Base的崛起更多是Coinbase的品牌效應+合規資源+用戶導流的結果,某種程度上也給Robinhood棲身於Arbitrum一定指導意義。
這意味着,短期看並不能證明 $ARB 的幣價被低估(對比看 $OP 的表現),但長期看,一旦Robinhood這次瞄準的“美股上鏈”場景跑通,可能會改變原本layer2作爲以太坊layer1擴展方案“有技術無落地”的尷尬局面,會給以太坊生態L1+L2都開拓出一條前所未有的Mass Adoption宏大路徑。
2)Coinbase做layer2更多還是通用layer2的解決方案,主要沿用了過往DeFi、GameFi、MEME等交易導向的場景,而Robinhood這次可能會不太一樣,會走專業化layer2的方向,專門爲傳統金融上鏈定制一套契合的鏈上基礎設施?
盡管OP-Rollup的交易確認時間也能做到亞秒級,但這類交易安全性本身都還在7天欺詐驗證的樂觀Rollup範疇內,而Robinhood的新layer2要處理股票T+0結算、實時風控、合規要求等特性,可能需要在layer2的虛擬機層面、共識機制、數據結構上做深度定制,把Lay

- 讚賞
- 點讚
- 留言
- 轉發
- 分享
一人,一騎,一咖啡,便是一整個麗江!——學會地理套利,用大自然和美景對沖市場的波動,這才是數字遊民應有的療愈慢生活。🚴☕️🏔️#數字遊民 你的療愈方式是什麼?
查看原文- 讚賞
- 點讚
- 留言
- 轉發
- 分享
在麗江大理遊玩時,和幾個一線Builder聊天,都不約而同提到一個感受:當下Crypto一級市場似乎正陷入一個“找不到出路”的多重危機中:
1)敘事徹底無意義化,賭場文化全面佔據主導?
其實,真正可怕的不是技術敘事無法Deliver,而是大家直接放棄敘事包裝,全面擁抱MEME化的賭場文化。
技術敘事交付慢至少還都是長期主義的事兒,有前期VC輪的創新成本Cover,也有項目方前期構建、測試、主網上線等Roadmap落地的過程,期間的透明化展示能幫助普通用戶認清項目的實力形成價值判斷。
但現在呢?一切都變成了純社區運營和背後資金博弈的遊戲,交易機會誇張到按天甚至按分鍾計。當市場不再圍繞技術敘事進行長期建設時,純MEME交易風險被成倍放大,對絕大多數人而言,這個市場會變得更加兇險。
2)開發者加速流失,技術創新陷入停滯?
數據不會撒謊。據有關數據,Github上活躍的Crypto開發者數量從去年高點下滑了近30%,而同期AI和傳統科技公司的工程師招聘Package卻在瘋狂漲。
邏輯很簡單,當OpenAI、Google、Meta都在AI軍備賽中爲構建硅基文明搶人的時候,Crypto那點"顛覆互聯網"的敘事情懷還能留住多少開發者?
關鍵是,Crypto經過兩三輪Build週期,現在開發者陷入一種創新熱情急速衰減的內耗階段,真正從0到1的技術突破少得可憐。Restaking、Intent、AI
查看原文1)敘事徹底無意義化,賭場文化全面佔據主導?
其實,真正可怕的不是技術敘事無法Deliver,而是大家直接放棄敘事包裝,全面擁抱MEME化的賭場文化。
技術敘事交付慢至少還都是長期主義的事兒,有前期VC輪的創新成本Cover,也有項目方前期構建、測試、主網上線等Roadmap落地的過程,期間的透明化展示能幫助普通用戶認清項目的實力形成價值判斷。
但現在呢?一切都變成了純社區運營和背後資金博弈的遊戲,交易機會誇張到按天甚至按分鍾計。當市場不再圍繞技術敘事進行長期建設時,純MEME交易風險被成倍放大,對絕大多數人而言,這個市場會變得更加兇險。
2)開發者加速流失,技術創新陷入停滯?
數據不會撒謊。據有關數據,Github上活躍的Crypto開發者數量從去年高點下滑了近30%,而同期AI和傳統科技公司的工程師招聘Package卻在瘋狂漲。
邏輯很簡單,當OpenAI、Google、Meta都在AI軍備賽中爲構建硅基文明搶人的時候,Crypto那點"顛覆互聯網"的敘事情懷還能留住多少開發者?
關鍵是,Crypto經過兩三輪Build週期,現在開發者陷入一種創新熱情急速衰減的內耗階段,真正從0到1的技術突破少得可憐。Restaking、Intent、AI
- 讚賞
- 點讚
- 留言
- 轉發
- 分享
大家都說以太坊Rollup-Centric戰略貌似失敗了?並深惡痛疾這種L1-L2-L3的套娃遊戲,但有意思的是,過去一年AI賽道的發展也走了一遍L1—L2—L3的快速演化。對比下,究竟問題出在哪裏?
1)AI的分層邏輯是,每層都在解決上層無法解決的核心問題。
比方說,L1的LLMs解決了語言理解和生成的基礎能力,但邏輯推理和數學計算確實是硬傷;於是乎到了L2,推理模型專門攻克這個短板,DeepSeek R1能做復雜數學題和代碼調試,直接補齊了LLMs的認知盲區;完成這些鋪墊之後,L3的AI Agent就很自然地把前兩層能力整合起來,讓AI從被動回答變成主動執行,能自己規劃任務、調用工具、處理復雜workflow。
你看,這種分層是“能力遞進”:L1打地基,L2補短板,L3做整合。每一層都在前一層基礎上產生質的飛躍,用戶能明顯感受到AI變得更聰明、更有用。
2)Crypto的分層邏輯是,每層都在爲前一層的問題打補丁,卻不幸帶來了全新更大的問題。
比如,L1公鏈性能不夠,很自然想到用layer2的擴容方案,但內卷了一波layer2 Infra潮之後貌似Gas低了、TPS累加提升了、但流動性卻分散了,生態應用還持續匱乏,使得過多的layer2 infra反倒成了大問題。於是乎開始做layer3垂直應用鏈,但應用鏈卻各自爲政,無法享受infra通用鏈的生態協同效應,用戶體驗反而更加碎片化
查看原文1)AI的分層邏輯是,每層都在解決上層無法解決的核心問題。
比方說,L1的LLMs解決了語言理解和生成的基礎能力,但邏輯推理和數學計算確實是硬傷;於是乎到了L2,推理模型專門攻克這個短板,DeepSeek R1能做復雜數學題和代碼調試,直接補齊了LLMs的認知盲區;完成這些鋪墊之後,L3的AI Agent就很自然地把前兩層能力整合起來,讓AI從被動回答變成主動執行,能自己規劃任務、調用工具、處理復雜workflow。
你看,這種分層是“能力遞進”:L1打地基,L2補短板,L3做整合。每一層都在前一層基礎上產生質的飛躍,用戶能明顯感受到AI變得更聰明、更有用。
2)Crypto的分層邏輯是,每層都在爲前一層的問題打補丁,卻不幸帶來了全新更大的問題。
比如,L1公鏈性能不夠,很自然想到用layer2的擴容方案,但內卷了一波layer2 Infra潮之後貌似Gas低了、TPS累加提升了、但流動性卻分散了,生態應用還持續匱乏,使得過多的layer2 infra反倒成了大問題。於是乎開始做layer3垂直應用鏈,但應用鏈卻各自爲政,無法享受infra通用鏈的生態協同效應,用戶體驗反而更加碎片化
- 讚賞
- 點讚
- 留言
- 轉發
- 分享
觀察了過去1個月泛AI領域的各種動向,發現一個很有意思的演進邏輯:web2AI從集中化——>分布式,web3AI從概念驗證——>實用性。二者正加速融合ing。
1)先看web2AI的發展動態,Apple的本地智能、各種離線AI模型的普及,背後反映的是AI模型正在變得更輕、更便捷。這告訴我們,AI的載體不再局限於大型雲服務中心,而是可以部署在手機、邊緣設備、甚至IoT終端上。
問題來了,當AI的載體變得高度分布式,如何確保這些分散運行的AI實例之間的數據一致性和決策可信度?
這裏有一層需求邏輯:技術進步(模型輕量化)→ 部署方式改變(分布式載體)→ 新需求產生(去中心化驗證)。
2)再來看web3AI的演進路徑,早期的AI Agent項目大多以MEME屬性爲主,但最近一段時間,市場從單純launchpad的炒作開始轉向更底層架構的AI layer1基礎設施系統性構建。
這裏又有一個逐漸清晰的供給邏輯:MEME炒作降溫(泡沫出清)→ 基礎設施需求顯現(剛需驅動)→ 專業化分工出現(效率優化)→ 生態協同效應(網路價值)。
你看,web2AI需求的“短板”正在逐漸靠近web3AI可供給的“長處”。web2AI和web3AI的演進路徑正逐步實現交匯。
web2AI在技術上越來越成熟,但缺乏經濟激勵和治理機制;web3AI在經濟模型上有創新,但技術實現卻落後於web2。二者融合正好可以優勢互
查看原文1)先看web2AI的發展動態,Apple的本地智能、各種離線AI模型的普及,背後反映的是AI模型正在變得更輕、更便捷。這告訴我們,AI的載體不再局限於大型雲服務中心,而是可以部署在手機、邊緣設備、甚至IoT終端上。
問題來了,當AI的載體變得高度分布式,如何確保這些分散運行的AI實例之間的數據一致性和決策可信度?
這裏有一層需求邏輯:技術進步(模型輕量化)→ 部署方式改變(分布式載體)→ 新需求產生(去中心化驗證)。
2)再來看web3AI的演進路徑,早期的AI Agent項目大多以MEME屬性爲主,但最近一段時間,市場從單純launchpad的炒作開始轉向更底層架構的AI layer1基礎設施系統性構建。
這裏又有一個逐漸清晰的供給邏輯:MEME炒作降溫(泡沫出清)→ 基礎設施需求顯現(剛需驅動)→ 專業化分工出現(效率優化)→ 生態協同效應(網路價值)。
你看,web2AI需求的“短板”正在逐漸靠近web3AI可供給的“長處”。web2AI和web3AI的演進路徑正逐步實現交匯。
web2AI在技術上越來越成熟,但缺乏經濟激勵和治理機制;web3AI在經濟模型上有創新,但技術實現卻落後於web2。二者融合正好可以優勢互
- 讚賞
- 點讚
- 留言
- 轉發
- 分享
比傳統KOL喊單更可怕的,是經過調教的AI Agent直接殺入交易一線。已經不是“信息差”的遊戲了,而是“執行力”的碾壓級代差。
傳統KOL再牛逼,也得靠肉眼盯盤、手動下單,從發現機會到完成交易中間隔着網路的延遲、還有手速的局限以及決策的不確定;
但AI Agent直接把這套流程壓縮到毫秒級——多鏈同步監控、算法識別套利窗口、自動化執行交易,整個過程無縫銜接。
So,AI Agent取代傳統KOL是遲早的事兒?
這個時間窗口正在快速打開,但還沒完全到位。從技術底層看,TEE可信執行環境、DeFi流動性基礎設施、跨鏈協議棧都還在探索磨合階段:
1、大部分AI Agent還停留在"單點突破"階段,真正的Multi-Agent軍團作戰模式還在構建期;
2、web3行業協議間還缺乏統一的API和權限管理標準化;
3、監管邊界還是一團漿糊,誰也不知道哪天會被一刀切,這讓很多資金方投鼠忌器;
4、鏈上Gas費和MEV搶跑成本還在吞噬大部分小額套利空間,只有大資金才玩得起這套遊戲;
5、真正懂Crypto原生邏輯又能寫出靠譜Agent的技術團隊還是稀缺資源,大部分項目都是web2思維硬套web3場景。
按這個發展速度,我估計2025年下半年就是個分水嶺。要避免淪爲這場AI交易大戰中的"人肉韭菜",出路只有一條:人人都得培養自己的AI Agent助理,徹底轉向Agentic思維玩轉Crypto。
查看原文傳統KOL再牛逼,也得靠肉眼盯盤、手動下單,從發現機會到完成交易中間隔着網路的延遲、還有手速的局限以及決策的不確定;
但AI Agent直接把這套流程壓縮到毫秒級——多鏈同步監控、算法識別套利窗口、自動化執行交易,整個過程無縫銜接。
So,AI Agent取代傳統KOL是遲早的事兒?
這個時間窗口正在快速打開,但還沒完全到位。從技術底層看,TEE可信執行環境、DeFi流動性基礎設施、跨鏈協議棧都還在探索磨合階段:
1、大部分AI Agent還停留在"單點突破"階段,真正的Multi-Agent軍團作戰模式還在構建期;
2、web3行業協議間還缺乏統一的API和權限管理標準化;
3、監管邊界還是一團漿糊,誰也不知道哪天會被一刀切,這讓很多資金方投鼠忌器;
4、鏈上Gas費和MEV搶跑成本還在吞噬大部分小額套利空間,只有大資金才玩得起這套遊戲;
5、真正懂Crypto原生邏輯又能寫出靠譜Agent的技術團隊還是稀缺資源,大部分項目都是web2思維硬套web3場景。
按這個發展速度,我估計2025年下半年就是個分水嶺。要避免淪爲這場AI交易大戰中的"人肉韭菜",出路只有一條:人人都得培養自己的AI Agent助理,徹底轉向Agentic思維玩轉Crypto。
- 讚賞
- 點讚
- 留言
- 轉發
- 分享
加密江湖風雲錄(一):乙巳年五月三十日實錄
序言:江湖夜雨十年燈
話說這加密江湖,自中本聰祖師開山立派以來,各路豪傑紛紛崛起,門派林立,恩怨糾葛不斷。今日且說這江湖中一日之內發生的種種風雲變幻,聽者莫不拍案稱奇。
第一回:新派崛起,InfoFi門顯神通
與此同時,Liquidium莊主於比特幣大會放出豪言,要將江湖中沉睡的四十億兩白銀統統喚醒,施展"跨鏈神功",讓死錢變活錢。江湖人士聞之,無不稱奇。
第二回:官府出手,正邪兩道皆震動
正午時分,忽有八百裏加急傳來:美利堅SEC衙門發布新規,明言"質押心法"並非旁門左道,此舉如甘露降臨,那以太坊門下弟子們歡聲雷動,皆言ETF大法指日可待。
更有CLARITY法案橫空出世,如九天雷音,震動朝野。江湖傳言,此法案乃兩黨聯手炮制,意在爲整個武林制定明規,從此正邪兩道皆有章法可循。
遠在意大利分舵,當地堂主卻傳出奇談:數字歐元心法比MiCA祕籍更爲重要,此言一出,引得各路門派議論紛紛。
第三回:AI劍客入江湖,新舊勢力相激蕩
正在此時,Magic Newton公子橫空出世,將AI劍法與跨鏈輕功合二爲一,如行雲流水,技驚四座。江湖中人見狀,皆言:新時代的武學,當如是也!
第四回:巨賈入局,以太坊版微策略現江湖
黃昏時分,忽聞一則驚天消息:SharpLink大財主宣布要籌集四億二千五百萬兩白銀,專門建立以太坊寶庫,江湖人士皆稱其爲"以太坊版微策略
查看原文序言:江湖夜雨十年燈
話說這加密江湖,自中本聰祖師開山立派以來,各路豪傑紛紛崛起,門派林立,恩怨糾葛不斷。今日且說這江湖中一日之內發生的種種風雲變幻,聽者莫不拍案稱奇。
第一回:新派崛起,InfoFi門顯神通
與此同時,Liquidium莊主於比特幣大會放出豪言,要將江湖中沉睡的四十億兩白銀統統喚醒,施展"跨鏈神功",讓死錢變活錢。江湖人士聞之,無不稱奇。
第二回:官府出手,正邪兩道皆震動
正午時分,忽有八百裏加急傳來:美利堅SEC衙門發布新規,明言"質押心法"並非旁門左道,此舉如甘露降臨,那以太坊門下弟子們歡聲雷動,皆言ETF大法指日可待。
更有CLARITY法案橫空出世,如九天雷音,震動朝野。江湖傳言,此法案乃兩黨聯手炮制,意在爲整個武林制定明規,從此正邪兩道皆有章法可循。
遠在意大利分舵,當地堂主卻傳出奇談:數字歐元心法比MiCA祕籍更爲重要,此言一出,引得各路門派議論紛紛。
第三回:AI劍客入江湖,新舊勢力相激蕩
正在此時,Magic Newton公子橫空出世,將AI劍法與跨鏈輕功合二爲一,如行雲流水,技驚四座。江湖中人見狀,皆言:新時代的武學,當如是也!
第四回:巨賈入局,以太坊版微策略現江湖
黃昏時分,忽聞一則驚天消息:SharpLink大財主宣布要籌集四億二千五百萬兩白銀,專門建立以太坊寶庫,江湖人士皆稱其爲"以太坊版微策略

- 讚賞
- 點讚
- 留言
- 轉發
- 分享
刚刚和几个圈内大佬聊完,大家都在讨论同一件事...
"四年一个周期"这套理论,彻底过时了!
如果你还在Hold住暴富,还在幻想"牛市十倍百倍的躺赢机会",可能已被市场完全抛弃了。Why?
因为聪明钱早就发现了一个秘密:现在的Crypto已不适用一套打法,而是4个完全不同的玩法周期在同时运行🧵:
每个玩法周期的节奏、玩法、赚钱逻辑都完全不一样。
——比特币超级周期:散户出局,十年慢牛或成定局
传统减半周期的"剧本"?彻底失效了!BTC已经从"炒作标的"进化成"机构配置资产",华尔街、上市公司、ETF的资金体量和配置逻辑,完全不是散户那套"牛熊切换"的玩法。
关键变化在哪?散户筹码正在大规模交出,而以MicroStrategy为代表的机构资金在疯狂进场。这种筹码结构的根本性重构,正在重新定义BTC的价格发现机制和波动特征。
散户面对的是什么?"时间成本"和"机会成本"的双重挤压。机构可以承受3-5年的持有周期来等待BTC的长期价值实现,而散户呢?显然不可能有这种耐心和资金布局实力。
在我看来,我们很可能会看到一个持续十年以上的BTC超级慢牛。年化收益率稳定在20-30%区间,但日内波动性显著降低,更像是一只稳健增长的科技股。至于BTC的价格上限会达到多少?以现在散户的视角去看,甚至都很难预测。
——MEME注意力短波周期:从贫民窟乐园到专业割韭菜场
MEME长牛论其实也成立,在技术叙
"四年一个周期"这套理论,彻底过时了!
如果你还在Hold住暴富,还在幻想"牛市十倍百倍的躺赢机会",可能已被市场完全抛弃了。Why?
因为聪明钱早就发现了一个秘密:现在的Crypto已不适用一套打法,而是4个完全不同的玩法周期在同时运行🧵:
每个玩法周期的节奏、玩法、赚钱逻辑都完全不一样。
——比特币超级周期:散户出局,十年慢牛或成定局
传统减半周期的"剧本"?彻底失效了!BTC已经从"炒作标的"进化成"机构配置资产",华尔街、上市公司、ETF的资金体量和配置逻辑,完全不是散户那套"牛熊切换"的玩法。
关键变化在哪?散户筹码正在大规模交出,而以MicroStrategy为代表的机构资金在疯狂进场。这种筹码结构的根本性重构,正在重新定义BTC的价格发现机制和波动特征。
散户面对的是什么?"时间成本"和"机会成本"的双重挤压。机构可以承受3-5年的持有周期来等待BTC的长期价值实现,而散户呢?显然不可能有这种耐心和资金布局实力。
在我看来,我们很可能会看到一个持续十年以上的BTC超级慢牛。年化收益率稳定在20-30%区间,但日内波动性显著降低,更像是一只稳健增长的科技股。至于BTC的价格上限会达到多少?以现在散户的视角去看,甚至都很难预测。
——MEME注意力短波周期:从贫民窟乐园到专业割韭菜场
MEME长牛论其实也成立,在技术叙

- 讚賞
- 點讚
- 留言
- 轉發
- 分享
这次攻击暴露的是一个经典的整数溢出问题,具体表现为类型转换过程中的数据截断。
技术细节拆解:
1)漏洞定位:问题出现在get_amount_by_liquidity函数的类型转换机制中,从u256到u64的强制转换导致高位数据丢失。
2)攻击流程:
1、攻击者通过add_liquidity函数传入极大的流动性数量参数;
2、系统调用get_delta_b函数计算所需的B代币数量;
3、在计算过程中,两个u128类型数据相乘,理论结果应为u256类型;
关键缺陷:函数返回时将u256结果强制转换为u64,导致高位128位数据被截断。
3)利用效果:原本需要大量代币才能铸造的流动性额度,现在仅需极少量代币即可完成。攻击者以极低成本获得巨额流动性份额,随后通过销毁部分流动性实现资金池套利。
简单类比:就像用只能显示8位数的计算器计算10亿×10亿,20位的计算结果只能显示后8位,前12位直接消失。攻击者正是利用了这种"计算精度缺失"漏洞。
Move语言在资源管理和类型安全方面确实具备显著优势,能够有效防范双重支付、资源泄露等底层安全问题。但此次Cetus协议出现的是应用逻辑层面的数学计算错误,并非Move语言本身的设计缺陷。
具体而言,Move的类型系统虽然严格,但对于显式类型转换(explicit casting)操作,仍需依赖开发者的正确判断。当程序主动执行u256到u64的类型转换
技术细节拆解:
1)漏洞定位:问题出现在get_amount_by_liquidity函数的类型转换机制中,从u256到u64的强制转换导致高位数据丢失。
2)攻击流程:
1、攻击者通过add_liquidity函数传入极大的流动性数量参数;
2、系统调用get_delta_b函数计算所需的B代币数量;
3、在计算过程中,两个u128类型数据相乘,理论结果应为u256类型;
关键缺陷:函数返回时将u256结果强制转换为u64,导致高位128位数据被截断。
3)利用效果:原本需要大量代币才能铸造的流动性额度,现在仅需极少量代币即可完成。攻击者以极低成本获得巨额流动性份额,随后通过销毁部分流动性实现资金池套利。
简单类比:就像用只能显示8位数的计算器计算10亿×10亿,20位的计算结果只能显示后8位,前12位直接消失。攻击者正是利用了这种"计算精度缺失"漏洞。
Move语言在资源管理和类型安全方面确实具备显著优势,能够有效防范双重支付、资源泄露等底层安全问题。但此次Cetus协议出现的是应用逻辑层面的数学计算错误,并非Move语言本身的设计缺陷。
具体而言,Move的类型系统虽然严格,但对于显式类型转换(explicit casting)操作,仍需依赖开发者的正确判断。当程序主动执行u256到u64的类型转换
- 讚賞
- 點讚
- 留言
- 轉發
- 分享